124
views

Viimati uuendatud

Uute veebisaitide omanike jaoks on üks suurimaid vigu nende robots.txt-faili uurimata jätmine. Mis see ikkagi on ja miks nii oluline? Meil on teie vastused.
Kui teil on veebisait ja hoolite oma saidi SEO-st, peaksite end oma domeeni robots.txt-failiga väga hästi kurssi viima. Uskuge või mitte, on häirivalt palju inimesi, kes käivitavad kiiresti domeeni, installivad kiire WordPressi veebisaidi ega viitsi oma robots.txt-failiga kunagi midagi teha.
See on ohtlik. Halvasti konfigureeritud fail robots.txt võib tegelikult hävitada teie saidi SEO tervise ja kahjustada teie liikluse suurendamise võimalusi.
Robots.txt fail on asjakohaselt nimetatud, kuna see on sisuliselt fail, mis loetleb veebirobotite (nt otsingumootorirobotite) direktiivid selle kohta, kuidas ja mida nad saavad teie veebisaidil indekseerida. See on olnud veebistandard, millele on veebisaidid järginud alates 1994. aastast ja kõik suuremad veebiröövijad järgivad seda standardit.
Fail salvestatakse teie veebisaidi juurkausta tekstivormingus (.txt-laiendiga). Tegelikult saate vaadata mis tahes veebisaidi robot.txt faili lihtsalt tippides domeeni, millele järgneb /robots.txt. Kui proovite seda rakendusega groovyPost, näete hästi struktureeritud robot.txt-faili näidet.
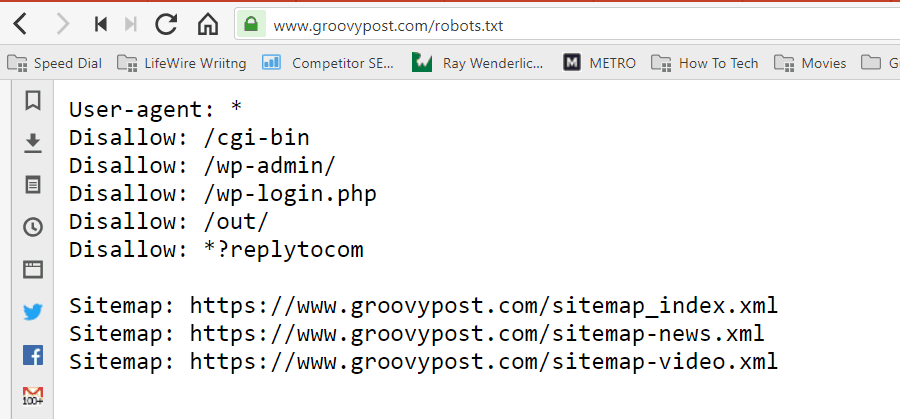
Fail on lihtne, kuid tõhus. Selles näidisfailis ei tehta robotite vahel vahet. Käsud antakse kõigile robotitele, kasutades nuppu Kasutaja agent: * direktiiv. See tähendab, et kõik sellele järgnevad käsud kehtivad kõigile robotitele, kes seda saiti külastavad, et seda roomata.
Samuti võiksite täpsustada konkreetsete veebi indekseerijate jaoks konkreetsed reeglid. Näiteks võite lubada Googlebotil (Google'i veebianduril) indekseerida kõik teie saidi artiklid, kuid võiksite keelata vene veebiröövel Yandex Bot indekseerida teie saidil artikleid, mille kohta on halvustavat teavet Venemaa.
Seal on sadu veebiandjaid, kes otsivad veebisaitide kohta teavet Internetist, kuid siin on loetletud kümme kõige tavalisemat, mille pärast peaksite muretsema.
Ülaltoodud näitestsenaariumi korral, kui soovite, et Googlebot saaks teie saidil kõike indekseerida, kuid soovite blokeerides Yandexi teie venekeelse artikli sisu indekseerimise, lisate robots.txt-le järgmised read faili.
Kasutajaagent: googlebot
Keela: Keela: / wp-admin /
Keela: /wp-login.php
Kasutajaagent: yandexbot
Keela: Keela: / wp-admin /
Keela: /wp-login.php
Keela: / venemaa /
Nagu näete, blokeerib esimene jagu Google'i ainult teie WordPressi sisselogimislehe ja administratiivlehtede indekseerimisega. Teine jaotis blokeerib Yandexi samast, aga ka kogu teie saidi alalt, kus olete avaldanud Venemaa-vastase sisuga artikleid.
See on lihtne näide, kuidas saate seda kasutada Keela käsk teie veebisaiti külastavate konkreetsete veebiandurite juhtimiseks.
Keelamine pole ainus käsk, millele teil failil robots.txt juurde pääseb. Võite kasutada ka mõnda muud käsku, mis juhendab, kuidas robot saab teie saiti indekseerida.
Pidage meeles, et robotid saavad ainult kuulake käske, mille olete andnud robotite nime täpsustamisel.
Tavaline viga, mida inimesed teevad, on selliste alade keelamine nagu / wp-admin / kõigist robotitest, kuid määrake seejärel googleboti sektsioon ja keelatakse ainult muud alad (näiteks / umbes /).
Kuna robotid järgivad ainult nende jaotises täpsustatud käske, peate kõigi nende robotite jaoks määratud kõik muud käsud uuesti kasutama (kasutades * user-agent).
Pidage meeles, et robots.txt on mõeldud selleks, et aidata seaduslikel robotitel (nt otsingumootorite robotitel) teie saiti tõhusamalt indekseerida.
Seal on palju varjamatuid indekseerijaid, kes indekseerivad teie saiti näiteks e-posti aadresside kraapimiseks või teie sisu varastamiseks. Kui soovite proovida oma robots.txt-faili kasutada, et takistada nende indekseerijatel teie saidil midagi roomamast, siis ärge häirige. Nende indekseerijate loojad ignoreerivad tavaliselt kõike, mille olete oma robots.txt faili lisanud.
Enamiku veebisaitide omanike jaoks on esmatähtis saada Google'i otsingumootor roomama oma veebisaidile võimalikult palju kvaliteetset sisu.
Google kulutab siiski ainult piiratud määral indekseerimise eelarve ja indekseerimise kiirus üksikutel saitidel. Roomamissagedus on see, kui palju taotlusi sekundis Googlebot teie saidile indekseerimise ajal esitab.
Veel olulisem on indekseerimiseelarve, mis näitab, mitu taotlust Googlebot teie saidi ühe seansi jooksul indekseerimise kohta esitab. Google kulutab indekseerimiseelarve, keskendudes teie saidi piirkondadele, mis on väga populaarsed või hiljuti muutunud.
Te pole selle teabe suhtes pime. Kui külastate Google Webmaster Tools, näete, kuidas roomik teie saiti haldab.
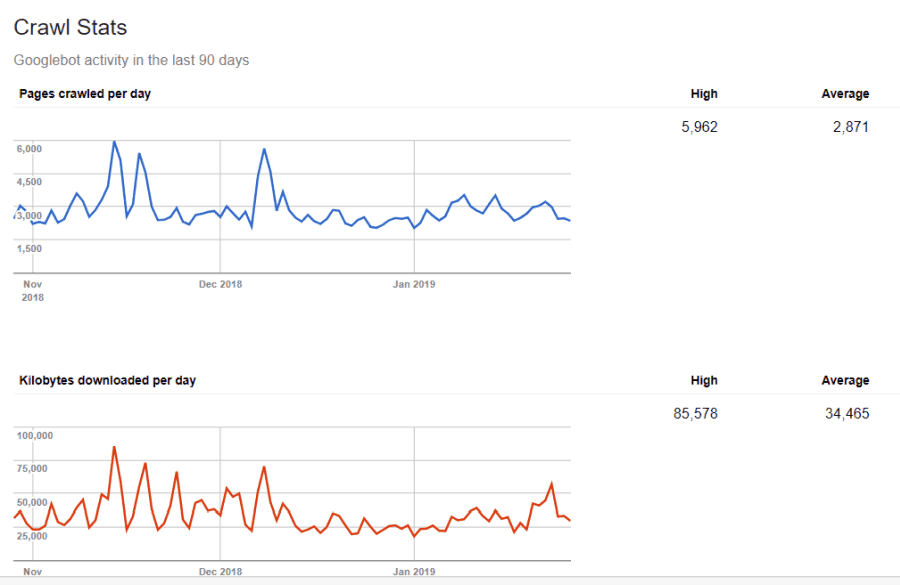
Nagu näete, hoiab roomik teie saidil iga päev üsna aktiivset tegevust. See ei indekseeri kõiki saite, vaid ainult neid, mida ta peab kõige olulisemaks.
Miks jätta Googleboti otsustada, mis on teie saidil oluline, kui saate robots.txt-faili abil öelda, mis on kõige olulisemad lehed? See hoiab ära Googleboti aja raiskamise teie saidi madala väärtusega lehtedel.
Google Webmaster Tools võimaldab teil kontrollida ka seda, kas Googlebot loeb teie faili robots.txt hästi ja kas selles pole vigu.
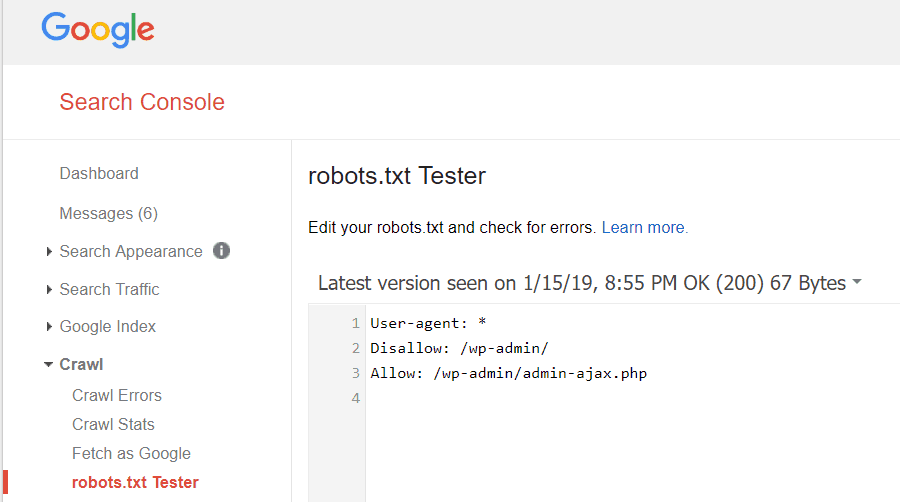
See aitab teil kontrollida, kas olete robots.txt faili õigesti struktureerinud.
Milliseid lehti peaksite Googlebotist keelama? On hea, kui teie saidi SEO keelab järgmiste kategooriate lehed.
Suurim viga, mida uued veebisaidi omanikud teevad, on kunagi isegi faili robots.txt vaatamine. Halvim olukord võib olla see, et fail robots.txt tõkestab teie saidi või teie saidi piirkondi tegelikult indekseerimisega.
Vaadake kindlasti üle oma fail robots.txt ja veenduge, et see oleks optimeeritud. Nii näevad Google ja muud olulised otsingumootorid kõiki neid vapustavaid asju, mida oma veebisaidiga maailmale pakute.

